🎙️ Transcription
Audio → text, in-browser, HIPAA-grade. Whisper WASM for clinical sessions; cloud Whisper for high-fidelity batch jobs. Audio never leaves the device unless the user explicitly opts into cloud upgrade.---
🎚️ Three-Path Transcription
| Path | Engine | When | Quality | Privacy |
|---|---|---|---|---|
| In-browser | Whisper WASM (Whisper.cpp compiled) | Default for live dictation, AAC voice input | Excellent for clear English/Spanish/French; noise-sensitive | ✅ Audio never leaves device |
| Server cloud | OpenAI Whisper-large-v3 via /api/v1/transcribe | Long-form batch jobs (1h+ session recordings); user opts in | Best — handles noise + accents + medical terminology | Audit-logged; HIPAA BAA in place |
| Live SOAP dictation | WhisperX (word-aligned timestamps) | Clinician dictating SOAP notes during session | Excellent + word timestamps for speaker-attribution | In-browser by default |
!Voice Dictation & Transcription
{kind=link}
---
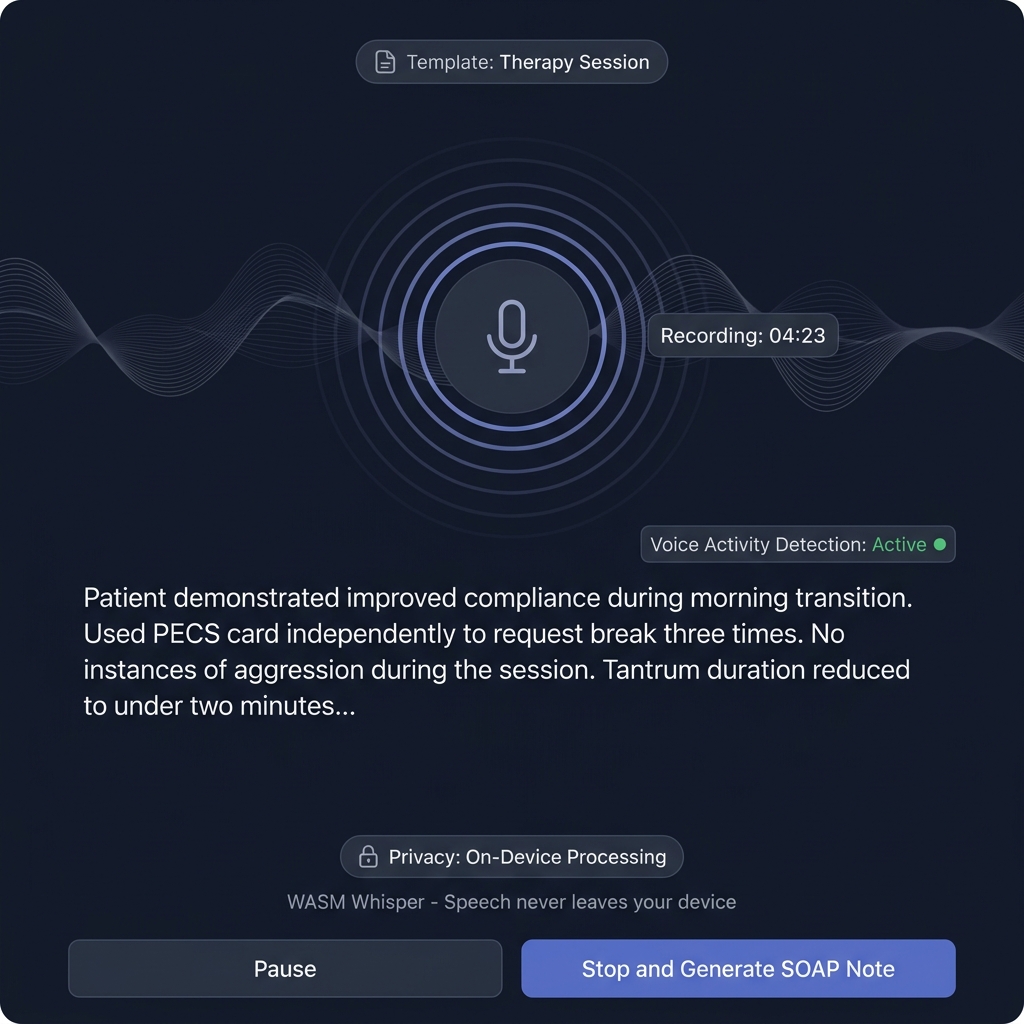
🩺 Live SOAP Dictation
The headline transcription use case. A clinician opens the session note, presses dictate, speaks the session out loud, and Synalux:
{kind=link}
See Applied Behavior Analysis and Clinical Notes Documentation for the downstream flow.
---
🗣️ AAC Voice Input
For Prism AAC users who can speak some words but use AAC for harder utterances:
* Whisper WASM transcribes speech in-browser, populates the keyboard input.
* Combined with autocorrect (Gemini 2.5 Flash-Lite) for typo recovery.
* Locale-aware: matches the user's chosen language; supports code-switching (e.g. EN words inside a RO sentence).
---
🏗️ Architecture
``
POST /api/v1/transcribe Server-side cloud Whisper (long-form, audit-logged)
body: { audio_url | audio_b64, lang?, model?='whisper-large-v3' }
returns: { text, segments[], language, duration_ms }
`
In-browser path (services/whisperService.ts):
---
⚖️ HIPAA + Privacy
* In-browser default — audio bytes never traverse Synalux infrastructure.
* Cloud upgrade requires explicit consent — UI shows a one-time consent gate per session before audio uploads.
* Audit logging — every cloud transcription writes to transcription_audit` with user, session, audio duration, model used.
* No retention — server-side audio bytes deleted within 24h of transcription; only the text result + audit row persist.
---
💳 Plans
| | Free | Standard | Advanced | Enterprise |
|---|---|---|---|---|
| In-browser Whisper (live dictation) | ✅ | ✅ | ✅ | ✅ |
| AAC voice input (in-browser) | ✅ | ✅ | ✅ | ✅ |
| Cloud Whisper-large-v3 (long-form) | — | ✅ 30 min/mo | ✅ 5 hr/mo | ✅ unlimited |
| Speaker-attribution (WhisperX) | — | — | ✅ | ✅ |
| Custom medical vocabulary boost | — | — | — | ✅ |
See full pricing →---
🔄 Inter-Module Integration
* SOAP / Clinical Notes — primary consumer; live dictation flow.
* Prism AAC — voice input → keyboard pre-fill.
* Telehealth — in-call live captions + recording-time transcription.
* Mail — voice replies (record → transcribe → edit → send).
* Translation — transcribed text can pipe directly into the Translation module.